DATABASE NORMALIZATION
Submitted By Uttam Kumar Paul (Department of BCA, Batch:2016-2019)
Normalization:-
Normalization is a technique for process of analyzing and decomposing a[1]relation schema into sub-relation based on their primary key and functional dependency to achive some desirable property.
Such Properties As,
1> minimizing redundancy. [2]
2> reducing the Null values in tuples.
3> minimizing insert, delete and update Anomalies [spurious tuple].
Ø Anomalies:- Without normalization many problems can occur when trying to load an integrated conceptual model into the DBMS. These problems arise from relations that are generated directly from user views are called anomalies.[3]
Ø Spurious Tuple:- A spurious tuple is, basically, a record in a database that gets created[4] when two tables are joined badly. In database, spurious tuples are created when two tables are joined on attributes that are neither primary keys nor foreign keys.
Ø Key Features Of Normalization:-
1> It enables faster sorting and index creation.[5]
2> Increase the compactness of the database.
3> create more clustered index.
Ø The Objective Of Normalization:-
” To create relations where every dependency is on the key, the whole key, and nothing but the key ”. [6]
Ø Some Important Terms Related To Normalization:- [7]
- Alternate Key:- An alternate key is a key associated with one or more columns whose values uniquely identify every row in the table, but which is not the primary key.
- Super Key:- The super key is reduced to the minimum number of columns required to uniquely identify each row.
- Candidate Key:- The Candidate key is a column, or set of columns that can uniquely identify a row in a table.
- Primary Key:- Primary key is a key which uniquely identifies a record. Primary keys are used to identify tables. There is only one primary key per table.
Ø Table Sales:-
|
#Scode |
Sname |
city |
status |
|
1001 |
A |
Kolkata |
100 |
|
1002 |
B |
Bangalore |
200 |
|
1003 |
C |
Mumbai |
300 |
Here, (Scode) is the primary key which uniquely identifies about the record.
- Foreign Key:- Foreign key are those keys which is used to define relationship between two tables. When we want to implement relationship between two tables then we use concept of foreign key. It is also known as referential integrity.
Ø Table Customer:-
|
#ccode |
Cname |
city |
comm |
Scode |
|
2001 |
X1 |
Kolkata |
0.1 |
1001 |
|
2002 |
X2 |
Kolkata |
0.2 |
1001 |
|
2003 |
X3 |
Mumbai |
0.3 |
1002 |
|
2004 |
X4 |
Bangalore |
0.4 |
1002 |
|
2005 |
X5 |
Delhi |
0.5 |
1003 |
|
2006 |
X6 |
Pune |
0.6 |
1003 |
Here, (Scode) is the foreign key which was primary key of sales table. So, it make a relation between two tables.
Here, sales and customer table.
Ø There Is a Sequence To Normal Form (for single value relationship):- [8]
Guideline for ensuring that DBs are normalized à normal forms: 1NF, 2NF, 3NF, BCNF.
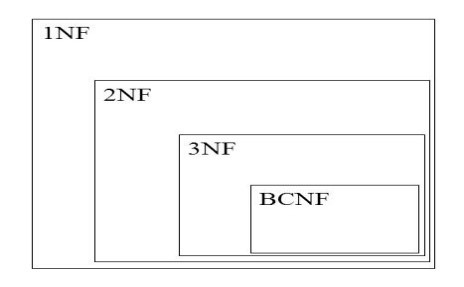
- 1NF is considered the weakest,
- 2NF is stronger than 1NF,
- 3NF is stronger than 2NF,
- BCNF is considered the strongest.
A relation in BCNF, is also in 3NF.
A relation in 3NF, is also in 2NF.
A relation in 2NF, is also in 1NF.
Ø First We Introduce The Concept Of Functional Dependency:-
Ø Functional Dependency:- Among the different data dependency that have been identified. [9]
so, for the concept of functional dependency is the most important one.
Definition: let, r is an instance of a relation R and X, Y ⊆R. The relation r satisfy the functional dependency X→Y if for two tuples t1, t2 of r, t1[X] = t2[X] implies t1[Y] = t2[Y].
Ø Table Customer:
|
Ccode |
Cname |
City |
Status |
|
1001 |
A |
Kolkata |
10 |
|
1002 |
B |
Pune |
18 |
|
1003 |
C |
Kolkata |
10 |
|
1004 |
D |
Pune |
18 |
Ø Table City:
|
City |
Status |
|
Kolkata |
10 |
|
Bangalore |
20 |
|
Chennai |
15 |
|
Pune |
18 |
|
Mumbai |
20 |
City→Status[Status functional dependences on City].
Ø Armstrong’s Axiom:- [10]
Armstrong’s Axiom are a set of axioms (or more precisely inference rules) used to infer all functional dependencies on a relational database. They were developed by William W. Armstrong in his 1974 paper.
Let R(U) be a relation scheme over the set of attributes U. Henceforth we will denote by letters X, Y, Z any subset of U and, for short, the union of two sets of attributes X and Yby XY instead of the usual X∪Y this notation is rather standard in database theory when dealing with sets of attributes.
Axiom of reflexivity:-If X is a set of attributes and Y is a subset of X, then X holds Y.
If Y⊆X then X→Y.
Axiom of augmentation:- If X holds Y and Z is a set of attributes, then XZ holds YZ. It means that attribute in dependencies does not change the basic dependencies.
If X→Y, then XZ→YZ for any Z.
Axiom of transitivity:- If X holds Y and Y holds Z, then X holds Z. X holds Y [X→Y] means that X functionally determines Y
If X→Y and Y→Z, then X→Z.
Ø Process Of Normalization:- [11]
Ø First Normal Form (1NF):- A relation schema is in 1NF if and only if (IFF), in every legal value of that relation each tuple must contains exactly one atomic value for each attributes.
|
NAME |
ADD |
ITEM |
PRICE |
|
A |
SRP |
X |
100 |
|
B |
KGP |
Y |
200 |
|
C |
HWH,BDC |
W |
150 |
|
D |
HWH |
--- |
300 |
The table is not 1NF as each tuple does not contains exactly one value for each attributes.
NOW,
NAME |
ADD |
ITEM |
PRICE |
A |
SRP |
X |
100 |
B |
KGP |
Y |
200 |
C |
HWH |
W |
150 |
C |
BDC |
W |
150 |
D |
HWH |
Z |
300 |
The example relation is in 1NF as each tuple contains exactly one value for each attributes.
Ø Second Normal Form (2NF):-A relation schema is in 2NF if and only if (IFF) It is in 1NF and every non prime attributes is fully functionally dependents on the prime attributes.
General Definition:- A relation schema is in 2NF IFF it must be in 1NF and every non key attributes is not partially dependent on the primary key of that relation.
Ø Emp_Proj:
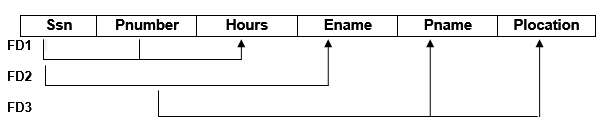
In above table, { Ssn, Pnumber } →Hours is fully dependency (either Ssn → Hourds nor Pnumber →Hours holds). However, the dependency { Ssn, Pnumber} → Ename is partial because Ssn →Ename holds.
So, we are decomposing the relation as –
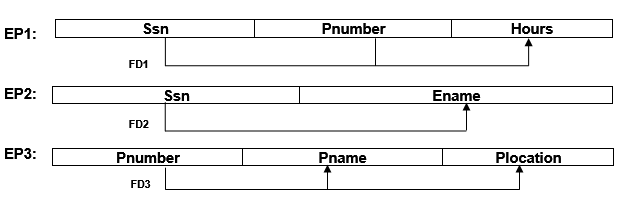
Now, these three relation is in 2NF as there is no partial dependency.
Ø Third Normal Form(3NF):- A relation schema is in 3NF IFF it is in 2NF and every non key attributes is non transitively dependent on primary key of that relation.
General Definition:- A relation schema is in 3NF, if a functional dependency XàA holds in R then either X is a super key of R or A is a prime attributes of R.

FD1: {NAME} → {ITEM}Now,
FD2: {ITEM} →{PRICE}
In the example relation FD2 forms is transitivity that’s why are decomposing the relation as-

Now, these two tables are in 3NF as there is no transitively.
ØBoyce Codd Normal Form (BCNF):- BNCF Developed by Raymond F. Boyce, Edgar F. Codd in 1974.
A relation is in BCNF if and only if every determinant is a candidate key.
NOTE, a relation which is in BCNF is in 3NF but the converse is not true because, a relation a relation is in 3NF if and only if every dependency A→B satisfied by R meets at least one of the following criteria:
- A→B is trivial (that is, B is a subset of A).
- A is a super key.
- B is a subset of a candidate key BCNF does not permit the 3rd of this option.
Therefore, BCNF is said to be stronger than 3NF because 3NF permit some dependencies which BCNF does not.
So, BCNF ⇒ 3NF but 3NF ≠ BCNF.
Ø Violation Of BCNF Happen Under Specific Condition:-
A relation contains two (or more) composite candidate key.
Which overlap and share at least one attributes in common.
Ø Transformation To BCNF:- remove violation functional dependencies by placing them in a new relation.
Ø Client-interview relation:
|
CLIENT_NO |
INTERVIEW_DATE |
INTERVIEW_TIME |
STAFF_NO |
ROOM_NO |
|
CR76 |
1 MAY 18 |
10:30 |
SG5 |
G101 |
|
CR56 |
8 MAY 18 |
12:00 |
SG5 |
G101 |
|
CR 74 |
10 MAY 18 |
11:00 |
SG37 |
G102 |
|
CR56 |
15 MAY 18 |
10:30 |
SG5 |
G102 |
The client interview relation has the following functional dependencies:
CLIENT_NO, INTERVIEW_DATE →INTERVIEW_TIME, STAFF_NO, ROOM_N0.
STAFF_NO, INTERVIEW_DATE, INTERVIEW_TIME → CLIENT_NO.
STAFF_NO, INTERVIEW_DATE → ROOM_N0.
Ø Interview relation:
|
CLIENT_NO |
INTERVIEW_DATE |
INTERVIEW_TIME |
STAFF_NO |
|
CR76 |
1 MAY 18 |
10:30 |
SG5 |
|
CR56 |
8 MAY 18 |
12:00 |
SG5 |
|
CR 74 |
10 MAY 18 |
11:00 |
SG37 |
|
CR56 |
15 MAY 18 |
10:30 |
SG5 |
Ø Staff-room relation:
|
STAFF_NO |
INTERVIEW_DATE |
ROOM_NO |
|
SG5 |
1 MAY 18 |
G101 |
|
SG37 |
10 MAY 18 |
G102 |
|
SG5 |
11 MAY 18 |
G102 |
INTERVIEW (CLIENT_NO, INTERVIEW_DATE, INTERVIEW_TIME, STAFF_NO)
STAFF-ROOM (STAFF_NO, INTERVIEW_DATE, ROOM_NO)
Ø Disadvantages Of Normalization:-[12]
- More tables to join: By spreading out your data into more tables, you increase the need to join tables.
- Tables contain codes instead of real data: Repeated data is stored as codes rather than meaningful data. Therefore, there is always a need to go to the lookup table for the value.
- Data model is difficult to query against: The data model is optimized for applications, not for ad hoc querying.
Ø How For The Companies Normalize:- [13]
The companies are used normalization because, many problems can occur when trying to load an integrated conceptual model into the DBMS. These problems arise from relations that are generated directly from user views are called anomalies. So, different types of are used different types of normalization process.
E.g:- TCS, IBM, WIPRO etc.
Ø Bibliography:-
[1] Data base system concepts, KORTH.
[2] Fundamental of Data base system, NAVATHE.
[3] DBMS.Wikipedia.com.
[4] www.spurioustuples.net.
[5] Fundamental of Data base system, NAVATHE.
[6] Data base concepts, KROENKE.
[7] DBMS-beginnersbook.com.
[8] www.studytonight.com.
[9] Data base system concepts, KORTH.
[10] en.m.wikipedia.org.
[11] Fundamental of Data base system, NAVATHE.
[12] www.GeeksofGeeks.com.
[13] en.m.wikipedia.com.